Generating Axios-style newsletters with AI and Natural Language Processing
Introduction
“Smart brevity”, a term coined by Axios, is a fantastic approach to disseminating lots of journalistic information quickly. It focuses on using a bullet-point format with short sentences or paragraphs rather than full paragraphs and prose. For those overwhelmed with news content and needing to review a large amount of it, this is a great way to read and review current events.
The smart brevity approach also lends itself well to algorithmic content. Here, we discuss how we built a news content generator and summarizer that authors an Axios-like newsletters. It does so by reading articles, analyzing them, and summarizing or outputting content via short, information-rich bullet points.
As a proof of concept (POC), we launched The Climate Sentinel to aggregate and summarize content for people interested in climate change and environmental issues, especially from a corporate or impact investing perspective. We’ll also discuss how this POC can be expanded to any topic or content set.
Vision
The smart brevity content structure presents a great opportunity for AI and natural language processing (NLP). Since you don’t need to create a full story with prose and beautifully chosen diction, it should be possible to find facts and statements about the world that can be stitched together into a coherent set of articles based on relevance to a topic.
With the right combination of content, facts, and text generation algorithms, one could theoretically create fully personalized Axios-like feeds for any individual set of interests, topic areas, or other article clusters. This is what Chimera Information Systems (CIS) set out to do in this experiment. We wanted to test how effective NLP and AI would be in automatically generating smart brevity-style news content that could be published on a website or inserted into an email.
Data Flow and Architecture
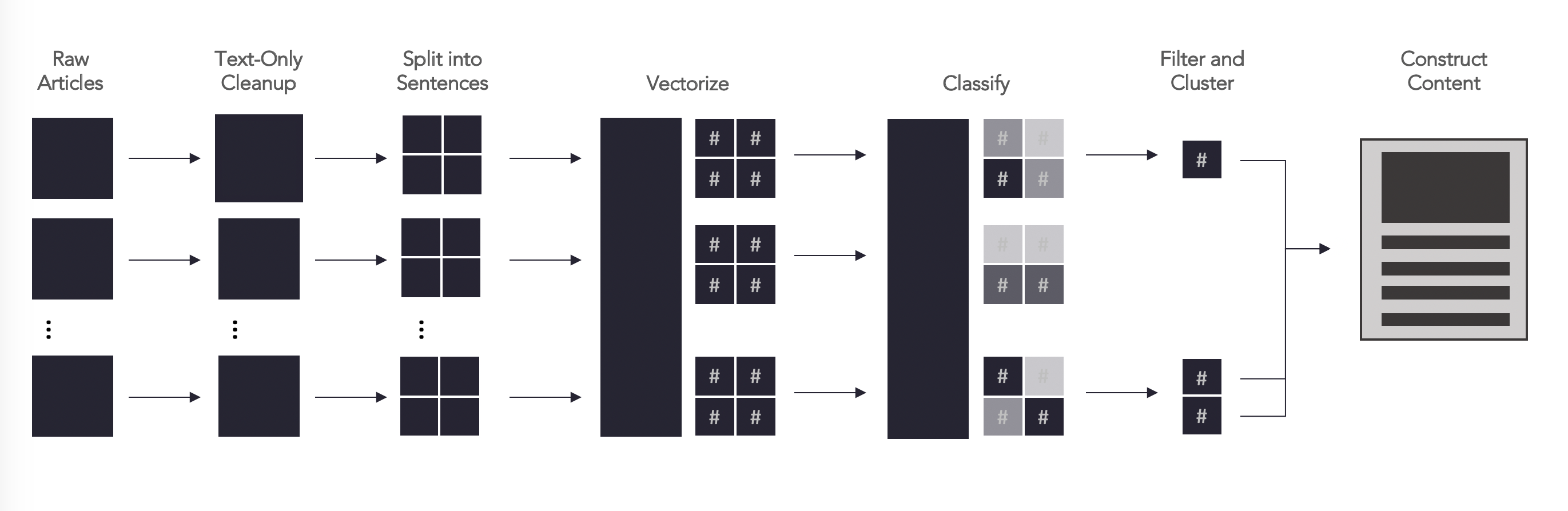
The diagram above shows how we structure the data flows and where we apply various types of algorithms to the data. We begin with content aggregation. We then clean and standardize all content, finally converting it into word vectors that can be analyzing with machine learning algorithms. We use a sentence-based approach – i.e., we analyze individual sentences – with the assumption that tidbits of important information are typically segregated into sentences. This isn’t always true, of course, but we find this works very well when trying to generalize across all pieces of content.
If you are curious about the software packages we use, check the appendix. Below, we discuss each of these steps in more detail.
Raw articles and reports. The first thing we need is actual content – ideally primary sources or opinion pieces, in cases where we might be doing a broader industry scan. We’re able to parse HTML, XML, PDFs, Word document, and text files.
Text-only cleanup. We begin by standardizing the data into a text-only format. This requires us to remove layout code, duplicate content such as footers and headers, images, and other information across different file formats. Each format requires a unique approach, which can be tedious and painful to customize for. We use a Python-based PDF parser (PyPDF2) for cleaning content from PDFs and BeautifulSoup4 for HTML.
Split into sentences. The sentence is the core component of what we analyze and work on. Each document, after being cleaned above, is split into a sequence of sentences. With this approach, we treat each article as an array of ordered sentences. This makes it easy to reference individual sentences, group sentences together based on similarity, or perform other operations.
Note also that we also classify information itself at the sentence level. To build training sets for our models, we’ll classify sentences based on whether they contain specific entities, whether they focus on a specific topic (i.e., binary classification or multiclass classification), and so on.
This approach also allows us to traverse documents near important sentences to get additional content, should we need it.
Vectorize. Next, we turn the sentences into word vectors; numerical representations of the sentences themselves. This is what we use for actual modeling, as this format can be used as an input into our machine learning libraries.
This is also where we can begin optimizing parts of the modeling process for specific modeling scenarios. We find that depending on what is being done (e.g., article summarization, sentence classification, entity extraction), different combinations of the processes below will result in data sets that are more or less effectively modelled.
- Stop words. We explore which words to filter out, or which to keep, based on frequency of words. We avoid remembering rare words or common ones, for example, and often will remove words like articles and prepositions.
- Conversion into arrays. Typically, we’ll use spaCy’s out-of-the-box models, or gensim’s data and model libraries. However, as our own database reaches over 1,000,000 articles, we’re finding better accuracy with our custom-built data models. In these scenarios, we use gensim’s Doc2Vec implementation to build word vectors at the sentence level.
Classify. The vectors above are then used within our classification models. We typically will find 50 or more sentences that match the sort of pattern that we are looking for and provide these as a training sample. As we use models more frequently, we tend to increase the data set to hundreds or thousands of positive human-labelled examples.
This process also becomes iterative. As we run daily news feeds or updates, we can label additional sentences to help tweak or improve the models with additional data. As a result, models improve significantly over time.
Our surprise has been how little “positive” examples we need to begin classifying sentences with “reasonable” accuracy – sometimes as little as 20 or 30. The challenge, in fact, has been framing the right sort of topic to classify around… Poorly defined topics don’t lend themselves to easy classification, even for humans.
Filter and cluster. We save the probability estimates for every model and every sentence. We can then filter articles based on rules combining relevance to a specific search, probability estimates by a model, entities in the sentence, or similarity to other sentences. For example:
- Find articles with at least x sentences above a probability threshold of y.
- Find articles where the title is above a certain probability estimate.
- Find articles that are classified under a specific topic but different (i.e., have a similarity score below a threshold) from other given articles.
- ...and so on.
You can also combine multiple models. For example, if we have models focused on biotech, investing, and space technology, you can also find articles that are classified above a probability threshold in all three, or at different probability thresholds.
Construct content. Finally, you can merge the sentences into an article, search interface, or other format that makes sense. In the case of The Climate Sentinel, we show article titles and pertinent text after passing all sentences through a “climate change” model. We rank articles by probability scores of their sentences and limit this approach to articles that and have at least three sentences above our probability threshold.
As such, the most relevant articles get selected, and only if they have sufficient content to include an outline of some sort.
Results
The Climate Sentinel shows how this software works in cases where we’re crawling about 5,000 to 6,000 pieces of content per day. The website is updated once a day but can be updated as frequently or infrequently as one would like. Articles can be selected over any time frame, though we focus on a 24-hour time frame to power our e-mail newsletter.
We’re now exploring how merging models could work, as this yields extremely relevant and interesting results. Here’s an example for Asia news and climate change. We applied two models – one on Asian news and one on climate change, and the top three relevant sentences are shown below:
Although smog levels this winter haven’t been as high as previous years, both residents and outsiders are concerned about China’s return to coal expansion. Chinese coal usage has grown in the last few years, despite China’s commitment to reducing its carbon emissions. That must end if China wants to meet its climate targets, a new report warns.
Concrete steps on carbon taxes and tariffs will have large implications for a global trading system already under strain from the Trump administration’s trade war against China and undermining of the World Trade Organization.
Emphasizing the need to stop China in particular from “subsidizing coal exports and outsourcing carbon pollution,” Biden’s stated platform pledges to make any bilateral U.S.-China climate agreement contingent on their cutting fossil fuel subsidies and lowering the carbon footprint of Belt and Road projects.
As you can see, this yields pretty good results!
Next Steps and Conclusion
We’re excited about launching content products, helping researchers do better research, and providing tools for journalists.
The above architecture is a baseline: it allows us to search articles, score sentences, and generate new content based on agglomerating sentences together. There are lots of additional NLP tools at our disposal – summarization to shorten content, detoxification or translation tools to change sentences, entity extraction to group sentences together in different ways, and so on.
In terms of what we’re focusing on as next steps, we have three major priorities:
- Improving classifiers, entity extraction, and other common NLP use cases.
- Extracting and building knowledge graphs from articles.
- Content generation via models like BERT, and approaches that actually yield factually correct results from automatic content generation. Plug-and-play models seem very promising for this work.
We think the natural language processing opportunity, especially around creating good content and workflows around news, is important... It’s important for journalism (and society!), and we believe working with a base of knowledge like this will make everyone better off. If you want to collaborate on this, let us know
Appendix: Preferred Software Packages
We’re a Python shop, so all of the tools we’re using are Python-oriented. Specifically:
- BeautifulSoup4 for any sort of HTML, XML and other format extraction and cleaning.
- gensim for building custom word vectors and vectorization in general (though we also use spaCy’s out-of-the-box models too)
- NLTK for some tokenization tasks.
- sci-kit learn for baseline models – these are often sufficient for building a reasonable test or user experience, though we do test different models and modelling approaches (both within sklearn and more broadly)
- spaCy for natural language processing, especially around word tokenization, sentence extraction, entity extraction, and part-of-speech labelling.